HashMapa jest to dynamicznie rozszerzalna struktura danych przechowująca pary <Klucz, Wartość> i działająca na zasadzie hashowania. Dane są nieuporządkowane a oczekiwana złożoność obliczeniowa dostępu do konkretnego obiektu poprzez klucz wynosi O(1). HashMapa jest klasą implementującą interface Map z Java Collections Framework.
Hashowanie
Powyższy krótki opis pojawia się prawie wszędzie tam gdzie jest pytanie co to jest HashMapa. Lecz nie dowiemy się z niego niczego istotnego na temat hashowania co jest kluczowe w świadomym i poprawnym korzystaniu z tej struktury. Aby to zrobić musimy wejść w sam środek klasy HashMap i dowiedzieć się naprawdę jest zbudowana.
Struktura HashMapy
HashMapa pod spodem jest tak naprawdę zwykłą tablicą przechowującą obiekty typu Node<K,V> i metody które na niej operują.
Kiedy deklarujemy zwykła tablicę w Javie zawsze musimy znać jej pojemność. Tak samo dzieje się przy HashMapie, jeżeli tego nie zrobimy wtedy pole CAPACITY będzie wstępnie ustawione na 16. Możemy ustawić ręcznie pojemność naszej mapy ale tylko raz i tylko przy jej inicjalizacji. Komórki nasze tablicy są również nazywane bucketami (kubełkami) co zostanie dalej omówione przy hashowaniu.
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16Jeżeli osiągniemy pewne zapełnienie naszej tablicy elementami, wtedy tablica dynamicznie się nadpisze na nowy rozmiar. Dynamiczne rozszerzanie HashMapy następuje automatycznie w momencie dodawania nowego elementu do mapy. Po dodaniu elementu następuje sprawdzenie warunku czy należy zwiększyć HashMapę czy też nie.
if (++size > threshold)
resize();Sprawdzenie powyższego warunku jest to porównanie aktualnego rozmiaru tablicy po dodaniu nowego elementu z progiem przejścia na nowy rozmiar. Próg (threshold) jest to iloczyn aktualnego rozmiaru tablicy i współczynnika przejścia DEFAULT_LOAD_FACTOR.
threshold = current capacity * DEFAULT_LOAD_FACTOR
threshold = 16 * 0.75 = 12 - przy początkowych wartościach mapyW powyższym przykładzie pierwszy raz mapa zwiększy swoją pojemność dopiero kiedy dodamy element numer 13 do mapy, ponieważ akceptowalnym progiem zapełnienia jest 12.
Tak samo jak przy pojemności, tak i przy współczynniku zapełnienia możemy indywidualnie go modyfikować według potrzeb byle był większy od 0 i z zakresu typu float.
* As a general rule, the default load factor (.75) offers a good
* tradeoff between time and space costs.Jeżeli nie mamy wyraźnej potrzeby zmiany współczynnika możemy spokojnie o nim zapomnieć. Sama dokumentacja mówi o tym, że jest to dobry kompromis pomiędzy czasem wyszukiwania a zajmowaną przestrzenią.
Obiekt typu Node
Obiekt Node jest wewnętrzną klasą tworzoną na potrzeby HashMapy. Każdy z obiektów tej klasy posiada 4 elementy.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}hash – jest to kopia hashcode klucza nowej pary <Klucz, Wartość>
key – jest to referencja do klucza
value – jest to referencja obiektu do którego odwołuje się klucz
next – jest to referencja do kolejnego obiektu o tym samym hashcodzie
Z powyższego możemy wyciągnąć wniosek dlaczego tak ważne jest aby kluczami były obiekty immutable (niezmienne).
Załóżmy, że mamy nową parę <Klucz, Wartość> przy czym klucz jest obiektem mutable. Gdy zapisujemy tą parę do mapy, wtedy na sztywno inicjujemy jego hashcode w obiekcie Node pod polem hash.
Jeżeli z innego miejsca zmienimy jakieś pola klucza poprzez referencję wtedy zmienimy jego hashcode. Jego nowy hashcode nie będzie zgadzał się z tym przypisanym do Node’a i zapisanego na sztywno. HashMapa nie odwołuje się do hashy kluczy tylko do pola hash którego dzięki słowu kluczowemu final nie możemy nadpisać.
Dostanie się przy pomocy tak zmodyfikowanego klucza spowoduje, że przez niezgodność hashy nie dostaniemy się do obiektu. Jeżeli jednak podalibyśmy klucz który przez przypadek miał by taki sam hash jak ten z pola hash obiektu Node to również nie dostaniemy się do obiektu ponieważ nasz klucz nie przejdzie porównywania pól metodą equals(). Taka sytuacja powoduje całkowitą destabilizacją pracy z daną Mapą. Dlatego tak ważne jest wykorzystywanie elementów immutable jako kluczy.
Zapis nowego obiektu
Zapisując nowy obiekt do HashMapy zapisujemy go do tablicy Node’ów w miejscu o odpowiednim indeksie tzw. bucket’cie. Ilość naszych bucket’ów jest to aktualna pojemność mapy. Załóżmy, że mamy początkową pojemność równa 16 i chcemy zapisać w nim nowy obiekt którego klucz posiada hash równy 25. Aby znaleźć odpowiedni indeks dla naszego nowego klucza musimy wykonać operację binarną AND która wygląda następująco.
tab[i = (n - 1) & hash]- Najpierw obliczamy wartość 'n-1′ czyli nasza pojemność tablicy minus jeden. 16 – 1 = 15
- Zamieniamy nasze liczby z systemu dziesiętnego na binarny
15 = 1111
25 = 11001- Wykonujemy operację binarna AND
1111 (n - 1) - 15
& 11001 (hash) - 25
-------
1001 (wynik) - 9Każdy hash o większej ilości bitów od pojemności tablicy jest skracany. W naszym przykładzie do 4 bitów. Następnie porównywane są te same bity. Jeżeli obydwa bity są ustawione na „1” wtedy w wyniku otrzymujemy „1”. Po porównaniu obydwu liczb otrzymujemy w systemie binarnym liczbę 1001 która odpowiada 9. w systemie dziesiętnym.
W ten łatwy sposób tylko na podstawie hashcode i rozmiaru tabeli HashMapa zapisuje obiekt do bucket’a. Podobnie wygląda odnajdywanie bucket’a w którym znajduje się szukany obiekt. Dzięki temu nie ma konieczności przeszukiwania całej mapy.
Bucket’y
Jak pisałem wcześniej początkowa pojemność standardowej tablicy w mapie jest to 16 elementów. Automatyczne zwiększenie jej pojemności następuje po zapełnieniu do 75%. W związku z czym przy zbliżaniu się do zapełnienia mapy nadal mamy wolne 25 lub… więcej procent elementów tablicy. Taka sytuacja ma miejsce wtedy gdy kilka kluczy ma takie same hashcody.
Jeżeli w jakimś elemencie tabeli znajduje się już jeden obiekt, kolejny jest zapisywany jako referencja w polu next. W ten sposób w danym bucket’cie tworzona jest LinkedLista obiektów o tym samym hashcodzie. W poniższym przykładzie w HashMapie znajdują się 4 pary <Klucz, Wartość>. Jeden w jednym bucket’cie, oraz 3 w drugim.
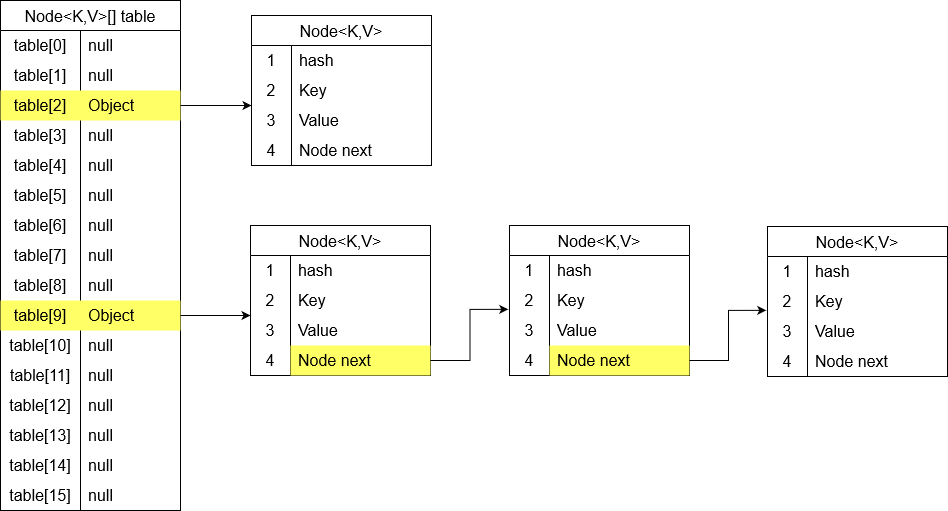
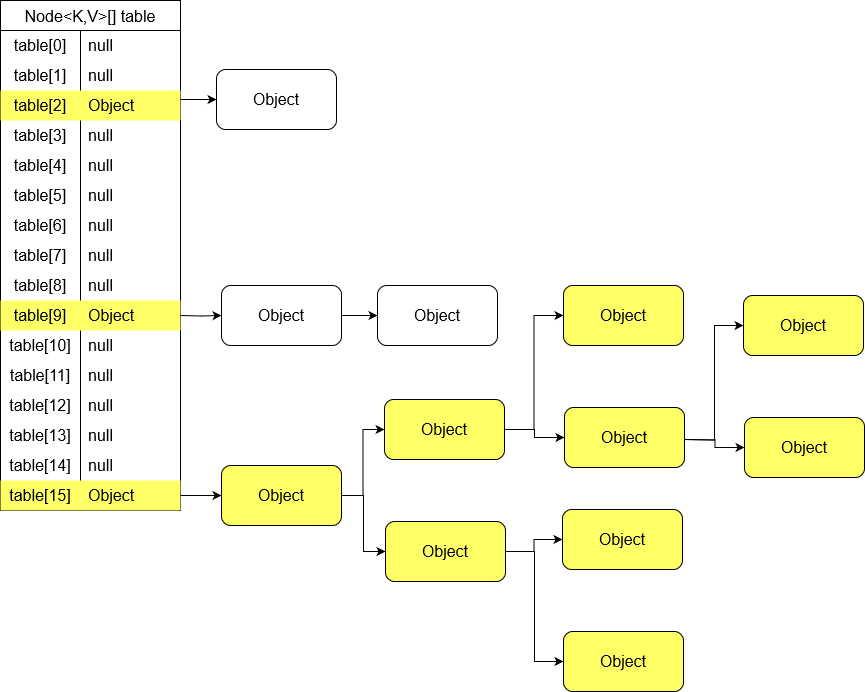
Standardowa oczekiwana złożoność obliczeniowa przy odczycie z HashMapy wynosi O(1). Przy zdegenerowanych danych gdzie wszystkie hashe są takie same mogłoby dojść do sytuacji, że w jednym bucket’cie mamy jedną długą LinkedListę obiektów. W takim przypadku złożoność obliczeniowa dążyła by do O(n). Java będzie porównywała klucz referencyjny po kolei z każdym kluczem w LinkedLiście za pomocą metody equals() aż znajdzie mu odpowiadający obiekt. Żeby zapobiec takim sytuacją twórcy Javy wprowadzili mechanizm red-black tree (czerwono-czarnego drzewa binarnego poszukiwań). Zamiana na RBT występuje w tych bucket’ach które przechowują co najmniej 8 elementów a cała tabela ma co najmniej 64 elementy. Zamiana mechanizmu LinkedListy na RBT powoduje spadek złożoności obliczeniowej dostępu do danych z O(n) do O(log n).
Czasy dostępu przy odczycie danych:
O(1) – oczekiwany
O(log n) – dla zdegenerowanych danych
O(n) – dla zdegenerowanych danych przy braku możliwości zastosowania red-black tree.
Zwiększenie objętości mapy
Po osiągnięciu przez mapę maksymalnej zajętości i próbie dodania kolejnego elementu mapa automatycznie zwiększy swoją pojemność. Przy nowej zmianie pojemnośc nasz pierwotny obiekt który miał hash równy 25, po operacji binarnej wpadał do bucket’a z indeksem równym 9. Teraz będzie się znajdował w innym bucket’cie.
Po zwiększeniu pojemności tablicy do 32 nasz obiekt wpadnie do bucketa równego 25. Tak samo wszystkie inne obiekty muszą być ponownie przepisane (następuje rehashing), a co za tym idzie cała struktura jest budowana na nowo wraz ze wszystkimi LinkedListami i drzewami binarnymi. Dlatego mimo iż oczekiwana złożoność obliczeniowa odczytu HashMapy wynosi O(1) to w przypadku kiedy akurat będzie następowało dynamiczne zwiększenie pojemności i rehashing wtedy będzie się zbliżała do O(n).
Podsumowanie
W powyższym artykule przedstawiłem jak działa hashowanie i zapis kluczy do HashMapy i dlaczego jego zrozumienie jest ważne do pisania bardzie odpornego na błędy kodu.
