HashMapa jest jedną z najpopularniejszych struktur danych z Java Collections Framework. HashMapa przechowuje dane w parach Kluch – Wartość, a wyszukiwanie elementów działa na zasadzie hashowania. Ten artykuł jest wstępem do zrozumienia HashMapy z pewnymi uproszczeniami do prostego zrozumienia podstaw mapy.
Budowa HashMapy
HashMapa jest to dynamicznie rozszerzalna struktura która przechowuje obiekty z przypisanym do niego kluczem. Kluczami oraz Wartościami mogą być tylko obiekty referencyjne. Z tego powodu nie możemy użyć typu prymitywnego np. „int” tylko klasy opakowującej „Integer”.
Map<Key, String> testMap = new HashMap<>();Identyfikacja obiektów działa na zasadzie hashowania, a sama struktura z punktu widzenia użytkownika jest nieuporządkowana i zmienna. Po dodaniu kilku obiektów mapa może zmienić całą swoją strukturę.
Do poprawnego działania HashMapy wymagane są:
- implementacja metody hashcode();
- implementacja metody equals();
- zadeklarowanie jako klucza obiektu nie mutowalnego
Poprawne to nie oznacza konieczne😉. Bez spełnienia tych warunków również stworzymy HashMapę, tylko jej zachowanie może być odmienne od oczekiwanego przez nas:)
Najczęściej używane metody HashMapy
Do najczęściej używanych metod które ułatwiają pracę programista należą:
- V put(Key, Value) – wstawia parę klucz – wartość do mapy. Jeżeli podany klucz już istnieje to przypisana do niego wartość zostaje nadpisana przez nową podaną przez użytkownika.
- V remove(Key) – usuwa prę klucz-wartość z mapy
- V get(Key) – zwraca wartość przypisaną do klucza, w przypadku błędnego klucza zwraca null
- boolean isPresent() – zwraca true jeżeli w mapie nie ma żadnych par
- int size() – zwraca liczbę par znajdujących się w mapie
- void clear() – usuwa wszystkie pary z mapy
- Set<K> setKey() – zwraca zbiór wszystkich kluczy z mapy (bez wartości)
- Collection<V> values() – zwraca wszystkie wartości z mapy (bez kluczy)
Zapis odczyt obiektów
Algorytm hash’ujący mapy- wersja uproszczona
Poniższy algorytm ma kilka uproszczeń ale dość dobrze obrazuje na podstawowym poziomie jak działa hashowanie w Javie.
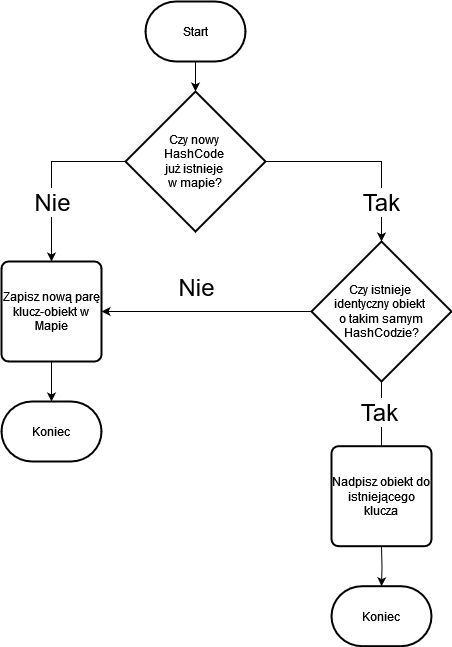
- Podczas próby zapisu nowego obiektu do mapy sprawdzane jest czy istnieje już klucz lub klucze o takim Hash Codzie. Wiele kluczy może mieć taki sam hash code.
- Jeżeli istnieją klucze o takim samym hash kodzie wtedy mapa porównuje nowy klucz z nimi. Porównanie następuje tylko z tymi obiektami dzięki czemu eliminujemy porównanie ze wszystkimi kluczami i wszystkimi polami co znacznie przyspiesza działanie programu.
- Jeżeli znajdziemy identyczny klucz (metoda equals zwróci true) to nowy obiekt który jest przypisany do klucza nadpisuje już istniejący. Jeżeli nie znajdzie identycznego klucza to tworzy nową parę klucz-obiekty o takim samym Hash Codzie.
W przypadku próby odczytu obiektu za pomocą podanego klucza mapa wykonuje takie same kroki jak przy zapisie. Jedyna różnica polega na tym, że w przypadku braku w mapie podanego klucza metoda zwróci wartość null.
Nie nadpisanie lub błędne nadpisanie metod equals() oraz hashCode()
Nie nadpisanie metody HashCode()
Załóżmy, że mamy klasę „KeyObject” która jest kluczem w naszej mapie. Posiada tylko jedno pole typu String, ale nie nadpisuje żadnej metody.
public class KeyObject {
String password;
}Nie nadpisanie metody HashCode() spowoduje użycie przez mapę domyślnej implementacji. Domyślna implementacja tworzy hash code na podstawie adresu obiektu w pamięci a nie jego pól. Taka sytuacja spowoduje, że obiekty które są identyczne będą posiadały różne hash cody. Nasze hash cody będą takie same jedynie kiedy będą miały taką samą referencje.
Jest to bardzo niepożądane ponieważ praktycznie nigdy nie moglibyśmy dostać się do danych znajdujących się w Mapie. Załóżmy, że mamy mapę której kluczem jest obiekt „KeyObject” przechowujący nazwę użytkownika i hasło a danymi które posiada użytkownik obiekt typu String. Poniższy przykład reprezentuje jak to może wyglądać.
Posiadamy domenę np. www.brakMetodHaszujących.pl gdzie:
- Posiadamy bazę użytkowników wraz z danymi (linia 1).
- Stworzyliśmy użytkownika o nazwie „User” wraz z hasłem oraz zapisaliśmy go do bazy danych.
1 Map<KeyObject, String> userData = new HashMap<>();
2 KeyObject keyA = new KeyObject();
3 keyA.user = "User";
4 keyA.password ="Password";
5 System.out.println(keyA.hashCode());
6 userData.put(keyA, "user data");
7 KeyObject keyFromUser = new KeyObject();
8 keyFromUser.user = "User";
9 keyFromUser.password ="Password";
10 System.out.println(keyFromUser.hashCode());
11 String dataFromBackend = userData.get(keyFromUser);
12 System.out.println("User data from map: " + dataFromBackend);Użytkownik się wylogował i chciał się ponownie zalogować
- Podaje dane – hasło i login
- Frontend wysyła dane do Backendu
- Backend tworzy nowy obiekt na podstawie danych i nazywa go keyFromUser (linie 7-9)
Po wykonaniu tego kodu chcielibyśmy wyświetlić dane użytkownika (w końcu obiekty „keyA” oraz „keyFromUser” są identyczne) w postaci:
User data from map: user dataNiestety przez brak metody hashCode() zamiast uzyskać powyższy komunikat otrzymujemy następujący:
250421012
1915318863
User data from map: nullNie jest to satysfakcjonujący wynik. Dzieje się tak dlatego, ponieważ jest tworzony nowy obiekt w pamięci. Brak nadpisanej metody hashCode powoduje, że domyślna tworzy hashCode na podstawie innego miejsca który jest różny od oczekiwanego.
Błędne nadpisanie metody HashCode()
Błędne nadpisanie metody hashCode jest bardziej zgodne z oczekiwaniami. Jeżeli mamy błędnie nadpisaną metodę hashCode w taki sposób, że np.
- Zawsze zwraca stałą liczbę
- Zwraca liczbę ale nie na podstawie wszystkich pól tylko kilku
Spowoduje to znaczne spowolnienie przeszukiwania mapy w celu znalezienia odpowiedniego klucza oraz przypisanej do niego obiektu. W pierwszym przypadku będziemy porównywać wszystkie klucze ze sobą element po elemencie co prowadzi do zmniejszenia wydajności z oczekiwanej O(1) do
- O(log n) w większości przypadków
- O(n) jeżeli pojemność mapy jest mniejsza od 64 (to nie to samo co ilość elementów w mapie)
W drugim przypadku możemy spowodować, że metoda haszująca będzie mniej wydajna od zamierzonej.
Nie nadpisanie metody equals()
Zakładamy, że poprawiliśmy nasz kod i nadpisaliśmy metodę hashującą. Teraz nasza klasa wygląda w następujący sposób:
public class KeyObject {
String user;
String password;
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((user == null) ? 0 : user.hashCode());
result = prime * result + ((password == null) ? 0 : password.hashCode());
return result;
}
}Niestety wyniki nadal nie będą się nam podobać. W rezultacie wykonania naszego kodu otrzymamy:
1363656689
1363656689
User data from map: nullW tym momencie pozytywnie przeszliśmy porównanie hashy. Niestety nienadpisanie metody equals powoduje, że porównywane są… miejsca w pamięci przechowywania danych, tak jak w pierwszym przykładzie.
Błędne nadpisanie metody equals()
Błędnie nadpisana metoda equals() spowoduje, że nie wszystkie pola będą porównywane ze sobą lub mogą być błędnie porównywane. Powyższe może prowadzić do niezgodności kontraktu hashcode-equals a co za tym idzie poprawnym wyszukiwaniem elementów.
Podsumowanie
Jestem pewien, że po przeczytaniu artykułu wiesz jak mniej więcej wygląda przeszukiwanie przez HashMapę jej elementów i jak ważne są implementacje metod hashCode() oraz equals(). Jest to dobry wstęp hashMapy. Aby ją w pełni zrozumieć należy dodatkowo zgłębić takie pojęcia jak:
- kontrakt hashCode i equals
- dlaczego klucze nie powinny być mutowalne
- jak działa hashowanie under the hood
